1. 請選出一個跟你論文主題相關的基因 (gene X)。
2. 將 gene X 於 Pubmed 或相關文獻探勘軟體,進行篇數,年代,作者趨勢分析。
3. 將 gene X 利用 NCBI Gene 入口,獲得相關序列資訊(包括 genomic, reference sequence, peptide sequence)
4. 利用 gene X 的序列進行 Blastn 或 Blastp,找出至少10條以上,20條以下,不同種 (species) 的序列,進行 Phylip 分析。使用方法為 NJ 與 ML。bootstrap 設定在 n = 250 。
5. 將 gene X 於 NCBI GEO profile 中尋找相關的表達資訊, 至少10個以上,20個以下。製成 tab txt file。再用 TMeV 畫出聚類分析圖形(至少三種)。
6. 將上述 5. 所得與 gene X 表達相關基因,利用 STRING 預測交互作用網路,並列出最有興趣的GO關係圖形 (CC, MF, BF) 三種。
7. 預測 gene X 的蛋白結構圖。
8. 預測 gene X 的 micorRNA binding site。
請於 1/14 前,上傳到各位的 blog, 並將未完成之實驗報告於 1/14 前補齊,以利評分。
----------------------------------------------------------------------------------------------------------
1. 請選出一個跟你論文主題相關的基因 (gene X)。
本次作業我選擇的gene X是: CD61
2. 將 gene X 於 Pubmed 或相關文獻探勘軟體,進行篇數,年代,作者趨勢分析。
利用Pubmed 和Pubmed PubReminer 搜尋 “CD61” 可搜尋到759篇相關的論文,自1990年便開始相關研究,由於它是血液細胞的marker,所以大部分論文都發表在血液學相關的期刊如Blood、Leukemia等。作者欄位可以看到埋頭于CD61研究的作者們,其中THIELE J、KVASNICKA HM及FISCHER R個別發表了最少26篇相關論文,且大部分研究都與代謝、免疫、藥物等相關。

若將搜尋條件改成 “CD61 Dengue”,最早的文章從2005年開始發表,截至今天只有8篇相關的論文,且可以看到彭老師的作品,共4篇。相關研究大部分以病毒學及代謝為主。

3. 將 gene X 利用 NCBI Gene 入口,獲得相關序列資訊(包括 genomic, reference sequence, peptide sequence)
從NCBI的入口中搜尋“CD61”可以得到很多結果,以本次作業的需求,我選了NM_000212。
這是個會轉錄出protein的gene,它位於第十七號染色體上 的q21.32位置。

它的genomic sequence就由下方的紅框所示

genomic: NG_008332.2 RefSeqGene
mRNA: NM_000212 Homo sapiens integrin subunit beta 3 (ITGB3)
protein: NP_000203 Integrin beta-3 precursor
peptide sequence:
"MRARPRPRPLWATVLALGALAGVGVGGPNICTTRGVSSCQQCLAVSPMCAWCSDEALPLGSPRCDLKENL
LKDNCAPESIEFPVSEARVLEDRPLSDKGSGDSSQVTQVSPQRIALRLRPDDSKNFSIQVRQVEDYPVDI YYLMDLSYSMKDDLWSIQNLGTKLATQMRKLTSNLRIGFGAFVDKPVSPYMYISPPEALENPCYDMKTTC LPMFGYKHVLTLTDQVTRFNEEVKKQSVSRNRDAPEGGFDAIMQATVCDEKIGWRNDASHLLVFTTDAKT HIALDGRLAGIVQPNDGQCHVGSDNHYSASTTMDYPSLGLMTEKLSQKNINLIFAVTENVVNLYQNYSEL IPGTTVGVLSMDSSNVLQLIVDAYGKIRSKVELEVRDLPEELSLSFNATCLNNEVIPGLKSCMGLKIGDT VSFSIEAKVRGCPQEKEKSFTIKPVGFKDSLIVQVTFDCDCACQAQAEPNSHRCNNGNGTFECGVCRCGP GWLGSQCECSEEDYRPSQQDECSPREGQPVCSQRGECLCGQCVCHSSDFGKITGKYCECDDFSCVRYKGE MCSGHGQCSCGDCLCDSDWTGYYCNCTTRTDTCMSSNGLLCSGRGKCECGSCVCIQPGSYGDTCEKCPTC PDACTFKKECVECKKFDRGALHDENTCNRYCRDEIESVKELKDTGKDAVNCTYKNEDDCVVRFQYYEDSS GKSILYVVEEPECPKGPDILVVLLSVMGAILLIGLAALLIWKLLITIHDRKEFAKFEEERARAKWDTANN PLYKEATSTFTNITYRGT"




4. 利用 gene X 的序列進行 Blastn 或 Blastp,找出至少10條以上,20條以下,不同種 (species) 的序列,進行 Phylip 分析。使用方法為 NJ 與 ML。bootstrap 設定在 n = 250 。
用NCBI內的BLAST程式搜尋相近的序列,將那些序列下載後用Phylip分析再用TreeView及HyperTree程式將其演化樹畫出。

ML: TreeView & HyperTree


NJ: TreeView & Hypertree


5. 將 gene X 於 NCBI GEO profile 中尋找相關的表達資訊, 至少10個以上,20個以下。製成 tab txt file。再用 TMeV 畫出聚類分析圖形(至少三種)。
我嘗試用CD61在 GEO Profile中搜尋相關資料,確實有找到類似的數據,可是基於一些原因,目前還無法將數據成功匯入TMev。
6. 將上述 5. 所得與 gene X 表達相關基因,利用 STRING 預測交互作用網路,並列出最有興趣的GO關係圖形 (CC, MF, BF) 三種。
由於在無法進行TMev的分析,只好直接在String上搜尋 "CD61" ,就可看到下圖:

搜尋結果:
可看到圖下方有許多相關蛋白質名稱以及其用途

GO - Cellular Component

Go - Molecular Function

Go - Biological Processes

7. 預測 gene X 的蛋白結構圖。
從 PDB中搜尋 “CD61” 可以看到至少11個結果。
選擇氨基酸數量最相近的2Q6W作為其預測的結果(如下圖)
從 PDB 網站預測的圖形

利用Pymol將蛋白質結構呈現

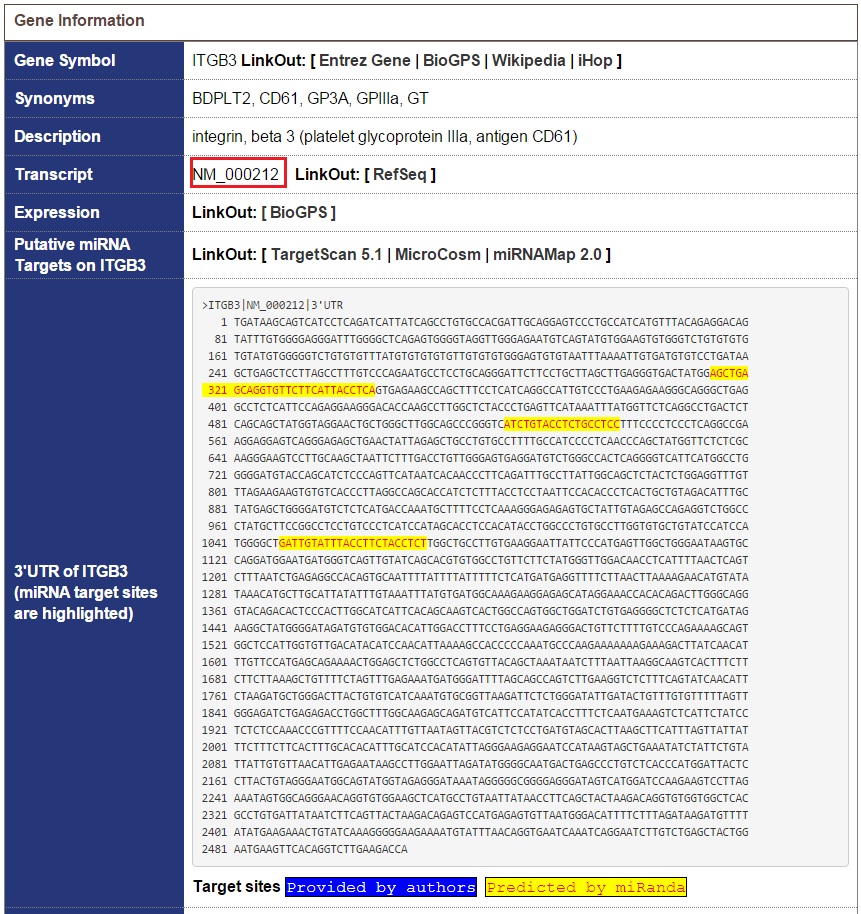
8. 預測 gene X 的 micorRNA binding site。
從 miRTarBase 這個網站中可以找到為數不少的CD61 microRNA,並且可以與NM_000212這條序列做binding。Binding site在下圖被黃色熒光筆標示出。


沒有留言:
張貼留言